模型生成文本基于目标音色的梅尔频谱图
声音克隆是指使用特定的音色,结合文字的读音合成音频,使得合成后的音频具有目标说话人的特征,从而达到克隆的目的。在训练语音克隆模型时,目标音色作为Speaker Encoder的输入,模型会提取这段语音的说话人特征(音色)作为Speaker Embedding。接着,在训练模型重新合成此类音色的语音时,除了输入的目标文本外,说话人的特征也将成为额外条件加入模型的训练。 在预测时,选取一段新的目标音色作为Speaker Encoder的输入,并提取其说话人特征,最终实现输入为一段文本和一段目标音色,模型生成目标音色说出此段文本的语音片段。
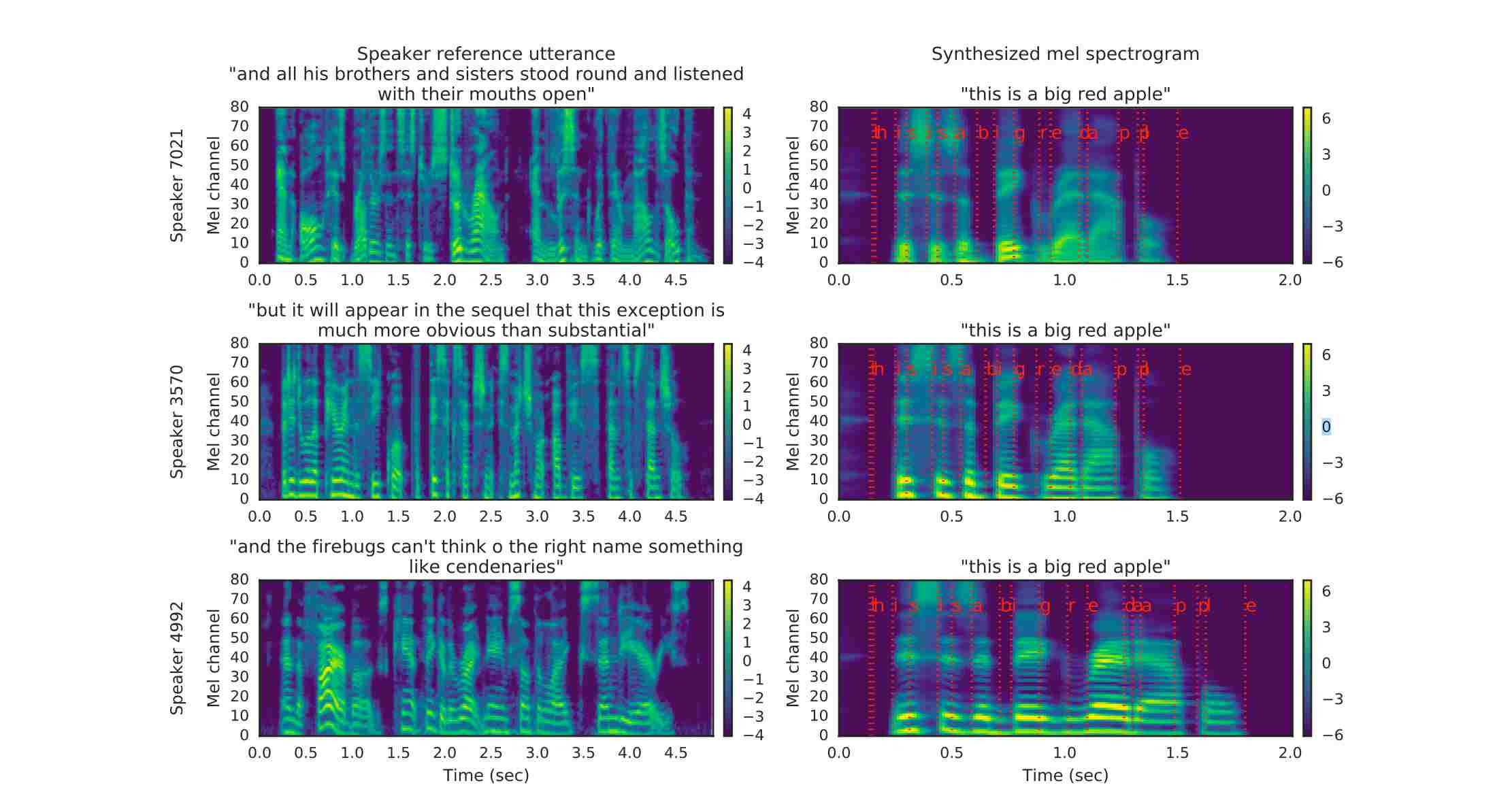
输入梅尔频谱图与合成频谱图的对比示例如下:
运行例子 - Tacotron2EncoderExample
运行成功后,命令行应该看到下面的信息:
...[INFO ] - 文本: 基于给定音色将文本转为梅尔频谱[INFO ] - 给定音色: src/test/resources/biaobei-009502.mp3
# 生成特征向量:[INFO ] - Speaker Embedding Shape: [256][INFO ] - Speaker Embedding: [0.06272025, 0.0, 0.24136968, ..., 0.027405139, 0.0, 0.07339379, 0.0][INFO ] - mel频谱数据 Shape: [80, 331][INFO ] - mel频谱数据: [-6.739388, -6.266942, -5.752069, ..., -10.643405, -10.558134, -10.5380535]
SDK代码下载地址: