Transformer的常用Tokenizer系列 - Java实现
这个sdk里包含了用于自然语言处理的tokenizer(分词器)。 切词输出的token序列,兼容huggingface(一个python实现的知名NLP库)。 java实现的Tokenizer有助于在java环境部署NLP模型。
包含的tokenizer如下:
- SimpleTokenizer
- BertTokenizer
- WordpieceTokenizer
- BertFullTokenizer
- ClipBPETokenizer
- GPT2Tokenizer(Todo)
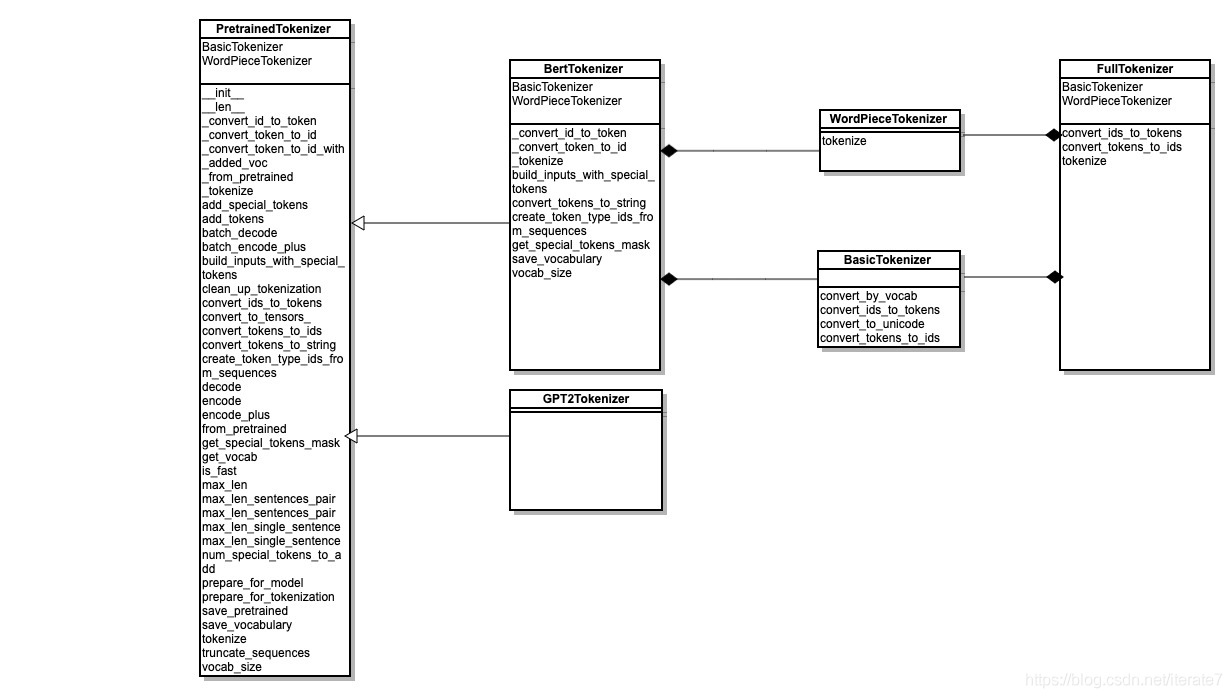
Python transformer 常用tokenizer:
运行例子
- 运行成功后,命令行应该看到下面的信息:
#BlazingText 测试文本:[INFO ] - testSimpleTokenizer:[INFO ] - Tokens: [This, tokenizer, generates, tokens, for, input, sentence]
[INFO ] - testBertTokenizer:[INFO ] - Tokens: [[CLS], When, did, Radio, International, start, broadcasting, ?, [SEP], Radio, International, was, a, general, entertainment, Channel, ., Which, operated, between, December, 1983, and, April, 2001, [SEP]][INFO ] - TokenTypes: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1][INFO ] - AttentionMask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[INFO ] - testWordpieceTokenizer:[INFO ] - Tokens: [[UNK], token, ##izer, generates, token, ##s, for, input, sentence]
[INFO ] - testBertFullTokenizer:[INFO ] - Tokens: [this, token, ##izer, generates, token, ##s, for, input, sentence]
[INFO ] - testClipBPETokenizer:[INFO ] - Tokens: [649, 751, 1628, 320, 22697]